DeeperAction Workshop @ ICCV2021
Challenge and Workshop on Localized and Detailed Understanding of Human Actions in Videos
Monday 11th October 2021


NEWS
- 2021-10-19
- Slides are now available at Program Schedule.
- 2021-10-05
- Winners are announced and reports can now be downloaded in Challenge Results.
- Details about our workshop schedule have been updated in Program Schedule.
- 2021-09-17
- 2021-09-10
- Due to a problem with the codalab server which causes uploading failure, we decide to postpone the test phase and winner annonuncement for 2 days.
- 2021-07-07
- Participants can now register on MultiSports (Track 2) - test. Please submit results for evaluation on this website.
- 2021-06-01
- We have published competitions for FineAction (Track 1), MultiSports (Track 2) and Kinetics-TPS (Track 3). Competitions start at June 1, 2021, midnight UTC and finish at Sept. 10, 2021, 11:59 p.m. UTC.
- Data for training and validation is now available on the competition pages above.
- 2021-05-26
Attending the Workshop
ICCV will once again be virtual this year and the workshop will be held on Monday 11th October 2021 as a half day event. Please refer to this page for more information.
Aims and Scope
DeeperAction aims to advance the area of human action understanding with a shift from traditional action recognition to deeper understanding tasks of action, with a focus on localized and detailed understanding of human action from videos in the wild. Specifically, we benchmark three related tasks on localized and detailed action understanding by introducing newly-annotated and high-quality datasets, and organize the action understanding challenge on these benchmarks.
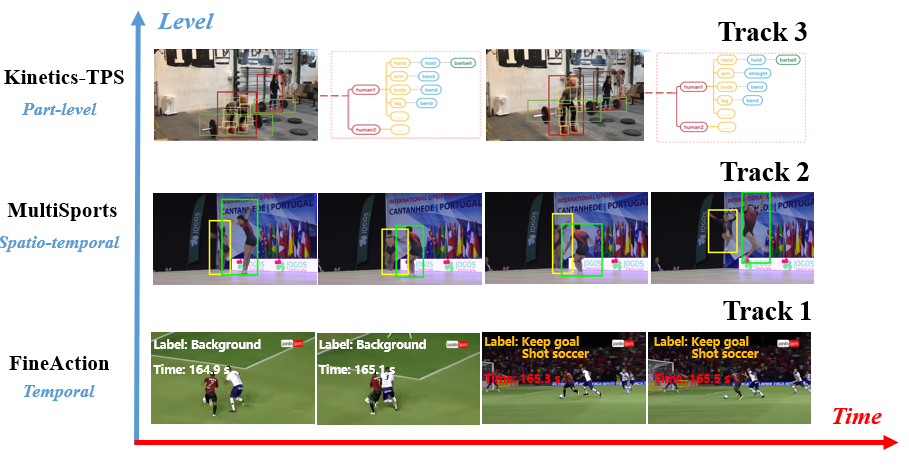
Temporal action Localization
Detecting all segments of containing actions of interest and recognizing their categories from a long video sequence.
Spatio-temporal action detection
Localizing all action instances with spatio-temporal tubes and recognizing their labels from untrimmed and multi-person videos.
Part-level action parsing
Decomposing the action instance into a human part graph and detecting action labels for all human parts an as well the whole human.